p02_ADPCM音频压缩算法的原理和实现
PCM数据格式介绍
1. What is PCM?
PCM(Pulse-code-modulation)是模拟信号以固定的采样频率转换成数字信号后的表现形式。
Sample Rate : 采样频率单位为:Hz。采样频率越高,音频质量越好,占用空间也越大。
Sign : 音频数据是否是有符号的。通常情况下都是有符号的。若是将有符号的数据当做无符号的数据来处理将会使声音听来很刺
Sample Size : 表示每一个采样数据的大小。通常该值为16-bit。
Byte Ordering : 字节序指的是little-endian还是big-endian。表示音频数据的存储字节序。通常均为little-endian。
Number of Channels : 标识音频是单声道(mono,1 channel)还是立体声(stereo,2 channels)。
通过以上五个数据我们就可以描述一个PCM数据,播放一个PCM数据需要的就是以上五个数据。
2. What does a PCM stream look like?
单声道:
500 | 300 | -100 | -20 | -300 | 900 | -200 | -50 | 250 |
每个整数占据2个字节(16-bit),9个采样也就是18字节的数据。每个采样的整数大小最小为 -32768,最大为 32768 。根据采样数据的位置和值画一个图的话,就会得到像播放器上那样的波浪形图。
我们可以像下面伪代码示例这样将数据读入一个C语言数组 :
FILE *pcmfileint16_t *pcmdata;
pcmfile = fopen(your pcm data file);
pcmdata = malloc(size of the file);fread(pcmdata, sizeof(int16_t), size of file / sizeof(int16_t), pcmfile);
如果我们将这些数据送入声卡,我们就可以听到声音。当然我们需要告诉声卡这些数据的采样率。若我们告知声卡的采样率大于数据本身的采样率,那么这些数据的播放速度会高于其原始的速度。就是快放的功能。
立体声:
| LFrame1 | RFrame1 | LFrame2 | RFrame2 | LFrame3 | RFrame3 | LFrame4 | RFrame4 | LFrame5 |
每一个frame是一个16-bit的采样点。左右声道的数据交叉存放。
3.Basic Audio Effects – Volume Control
现在让我们来看一下一些真实的波形图。最简单的就是正弦波了。
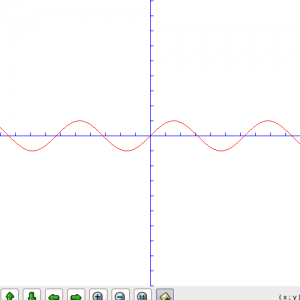
我们将波形的振幅扩大五倍,图形如下:
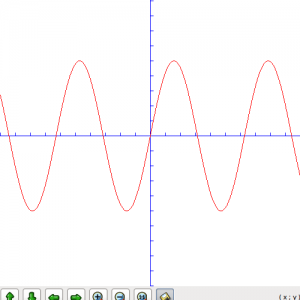
所以如果要增加PCM数据的音量,只需要将每一个采样的数据乘以一个系数就行了。如果我们的PCM数据有2048个字节,则包含了1024个采样。我们用如下的伪代码来扩大音量 :
音量控制就是这么简单,但是要注意两点:
若采样点的数据乘以扩大系数之后的值 小于 -32768 或 大于 32768 ,则此处采样的数值只能取 -32768 或 32768
int16_t pcm[1024] = read in some pcm data;
int32_t pcmval; for (ctr = 0; ctr < 1024; ctr++) {
pcmval = pcm[ctr] * 2; if (pcmval < 32767 && pcmval > -32768) {
pcm[ctr] = pcmval
} else if (pcmval > 32767) {
pcm[ctr] = 32767;
} else if (pcmval < -32768) {
pcm[ctr] = -32768;
}
}
以上内容翻译自:http://www.ypass.net/blog/2010/01/pcm-audio-part-3-basic-audio-effects-volume-control/
4. How to change PCM Sample Rate
根据定义,Sample Rate表示每秒钟的采样个数,所以若是要改变音频的采样频率,我们只需要对采样点做适当的丢弃或者复制就可以。
比如:原始音频为opus编码,单声道,采样率为48kHz,采样点大小为16-bit。如何得到编码为speex,采样率为16kHz,采样大小为16-bit的音频? 我们需要以下几步: + 将opus解码为PCM格式数据(叫做PCM1),此时的PCM1的采样率为48kHz + 将PCM1的数据中第 3*n(n为从0开始的自然数) 个位置的采样点,丢弃3*n+1 和3*n+2位置的采样点。得到PCM2,此时的PCM2采样率为48kHz / 3 = 16kHz + 将PCM2编码为speex数据
5. PCM的文件头格式
windows下文件的开始部分都有特定的文件头来存储文件的格式和数据类型和长度,PCM文件也不例外,他还要存放上面提到的采样率等信息,他的格式如下:
//pcm 文件头格式
unsigned char pcmHeader[] = {
'R', 'I', 'F', 'F',
0x00, 0x00, 0x00, 0x00,//datalen + sizeof(pcmHeader) - 8;
'W', 'A', 'V', 'E',
'f', 'm', 't', ' ',
0x10, 0x00, 0x00, 0x00,
0x01, 0x00,
0x00, 0x00,//channels
0x00, 0x00, 0x00, 0x00,//sample rate
0x00, 0x00, 0x00, 0x00,//nAvgBytesperSec
0x00, 0x00,//blockalign
0x10, 0x00,//bitspersample
'd', 'a', 't', 'a',
0x00, 0x00, 0x00, 0x00//datalen
};
//adpcm 文件头格式
unsigned char adpcmHeader[] = {
'R', 'I', 'F', 'F',
0x00, 0x00, 0x00, 0x00,//datalen + sizeof(adpcmHeader) - 8;
'W', 'A', 'V', 'E',
'f', 'm', 't', ' ',
0x14, 0x00, 0x00, 0x00,
0x11, 0x00,
0x00, 0x00,//channels
0x00, 0x00, 0x00, 0x00,//sample rate
0x00, 0x00, 0x00, 0x00,//nAvgBytesperSec
0x00, 0x00,//blockalign
0x04, 0x00,//bitspersample
0x02, 0x00,
0x00, 0x00,//samples of a block
'f', 'a', 'c', 't',
0x04, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00,//totalframes
'd', 'a', 't', 'a',
0x00, 0x00, 0x00, 0x00//datalen
};
表1 8KHz采样、16比特量化的线性PCM语音信号的WAVE文件头格式表(共44字节)
偏移地址 字节数 数据类型 内容 文件头定义为
00H 4 char "RIFF" char riff_id[4]="RIFF"
04H 4 long int 文件总长-8 long int size0=文总长-8
08H 8 char "WAVEfmt " char wave_fmt[8]
10H 4 long int 10 00 00 00H(PCM) long int size1=0x10
14H 2 int 01 00H int fmttag=0x01
16H 2 int int channel=1 或2
18H 4 long int 采样率 long int samplespersec
1CH 4 long int 每秒播放字节数 long int bytepersec
20H 2 int 采样一次占字节数 int blockalign=声道数*量化数/8
22H 2 int 量化数 int bitpersamples=8或16
24H 4 char "data" char data_id="data"
28H 4 long int 采样数据字节数 long int size2=文长-44
2CH 到文尾 char 采样数据
表4 ADPCM语音编码后的WAVE文件头格式表(共90字节)
偏移地址 字节数 数据类型 内容 文件头定义为
00H 4 char "RIFF" char riff_id[4]="RIFF"
04H 4 long int 文件总长-8 long int size0=文总长-8
08H 8 char "WAVEfmt " char wave_fmt[8]
10H 4 long int 32000000H(ADPCM) long int size1=0x32
14H 2 int 02 00H int fmttag=0x02
16H 2 int 声道数 int channel=1 或2
18H 4 long int 采样率 long int samplespersec
1CH 4 long int 每秒播放字节数 long int bytepersec
20H 2 int 采样一次占字节数 int blockalign=声道数*量化数/8
22H 2 int 量化数 int bitpersamples=4
24H 34 char 固定字节 char temp1
46H 4 char "fact" char wave_fact="fact"
4AH 8 char 0400000004930600H定 char temp2
52H 4 char "data" char wave_data="data"
56H 4 long int 采样数据字节数 lont int size2=文长-90
5AH 到文尾 采样数据
二、ADPCM压缩算法
因为pcm数据是直接存储,数据量比较大,那这时候就需要一种压缩算法来减小大小。于是IMA-ADPCM压缩算法就出现了,它可以实现4:1的压缩比,而且算法简单,适合嵌入式系统使用。
adpcm编解码原理
要理解adpcm编码,我们先来讲DPCM编码
差分脉冲编码调制(Differential Pulse code modulation,DPCM),是一种对模拟信号的编码模式,与PCM不同每个抽样值不是独立的编码,而是先根据前一个抽样值计算出一个预测值,再取当前抽样值和预测值之差作编码用.此差值称为预测误差.抽样值和预测值非常接近(因为相关性强),预测误差的可能取值范围比抽样值变化范围小.所以可用少几位编码比特来对预测误差编码,从而降低其比特率.这是利用减小冗余度的办法,降低了编码比特率。
DPCM编码在差值较大的时候相对于原始曲线偏差较大,所以前辈们改进了算法,采取自适应的量化去编码不同的偏差,于是就出现了ADPCM编码。
ADPCM(Adaptive Differential Pulse Code Modulation——自适应差分脉冲编码调制) ADPCM综合了APCM的自适应特性和DPCM的差分特性,是一种性能比较好的波形编码。它的核心想法是:1.利用自适应改变量化阶的大小,即使用小的量化阶去编码小的差值,使用大的量化阶去编码大的差值。2.使用过去的样本值估算下一个输入样本的预测值,使实际样本也预测值之间的差值总是最小。
adpcm编码原理

编码步骤:
- 求出输入的pcm数据与预测的pcm数据(第一次为上一个pcm数据)的差值diff;
- 通过差分量化器算出delta(通过index(首次编码index为0)求出step,通过diff和step求出delta)。delta即为编码后的数据;
- 通过逆量化器求出vpdiff(通过求出的delta和step算出vpdiff);
- 求出新的预测valpred,即上次预测的valpred+vpdiff;
- 通过预测器(归一化),求出当前输入pcm input的预测pcm值,为下一次计算用;
- 量化阶调整(通过delta查表及index,计算出新的index值)。为下次计算用;
adpcm解码原理
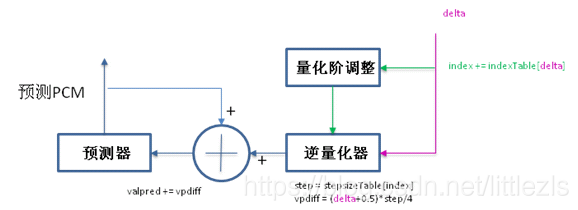
解码步骤(其实解码原理就是编码的第三到六步):
- 通过逆量化器求出vpdiff(通过存储的delta和index,求出step,算出vpdiff);
- 求出新的预测valpred,即上次预测的valpred+vpdiff;
- 通过预测器(归一化),求出当前输入pcm input的预测pcm值,为下一次计算用。预测的pcm值即为解码后的数据;
- 量化阶调整(通过delta查表及index,计算出新的index值)。为下次计算用;
算法代码及实现demo: PC平台: https://github.com/ShowerXu/IMA-ADPCM 使用CodeBlocks打开编译 用法:
ima-adpcm.exe -[edr] INPUT.wav OUTPUT.wav
# 参数对应含义
-e: encode mode (PCM wav -> IMA-ADPCM wav) 编码
-d: decode mode (IMA-ADPCM wav -> PCM wav) 解码
-r: output residual (PCM wav -> Residual PCM wav) 输出偏差值
三、 ADPCM数据存放形式
本部分为adpcm数据存放说明,属于细节部分,很多代码解码出来有噪音就是因为本部分细节不对,所以需要仔细阅读。
- adpcm 数据块介绍 adpcm数据是一个block一个block存放的,block由block header (block头) 和data 两者组成的。其中block header是一个结构,它在单声道下的定义如下:
Typedef struct
{
short sample0; //block中第一个采样值(未压缩)
BYTE index; //上一个block最后一个index,第一个block的index=0;
BYTE reserved; //尚未使用
}MonoBlockHeader;
对于双声道,它的blockheader应该包含两个MonoBlockHeader其定义如下:
在解压缩时,左右声道是分开处理的,所以必须有两个MonoBlockHeader;有了blockheader的信息后,就可以不需要知道这个block前面数据而轻松地解出本block中的压缩数据。故adpcm解码只与本block有关,与其他block无关,可以只单个解任何一个block数据。 block的大小是固定的,可以自定义,每个block含的采样数nsamples计算如下:
//
#define BLKSIZE 1024
block = BLKSIZE * channels;
//block = BLKSIZE;//ffmpeg
nsamples = (block - 4 * channels) * 8 / (4 * channels) + 1;
注:只有按照该格式编码出来的adpcm文件才能被播放器正确识别和播放.
- adpcm数据块格式:
单通道 16bit pcm数据格式
| byte 0 byte 1 | byte 2 byte 3 | byte 4 byte 5 | byte 6 byte 7 | byte 8 byte 9 | byte n byte n+1 |
|---|---|---|---|---|---|
| sample0 | sample1 | sample2 | sample3 | sample4 | sample n/2 |
单通路压缩为adpcm数据为 4bytes block head + raw data:
| byte 0 byte 1 | byte 2 | byte 3 | byte 4 | byte 5c | byte n |
|---|---|---|---|---|---|
| sample0 | index | reserved | data0 | data1 | data n-4 |
byte0~byte1存储的是16bits的基础采样值,byte2为之前的索引值(第一个block为0),byte3保留为0;
后面的每一个byte数据包含两个4bits的偏差量化值。其中sample1编码后存data0低4位,sample2编码后存data0高四位...
所以在单通道16bit adpcm编码下,每一个block存储的采样数为 (block数量-4)*2+1; 所以block为1024的时候解码后的采样值数量为2041.
双通路pcm格式:
| byte 0 byte 1 | byte 2 byte 3 | byte 4 byte 5 | byte 6 byte 7 | byte 8 byte 9 | byte 10 byte 11 |
|---|---|---|---|---|---|
| sampleL0 | sampleR0 | sampleL1 | sampleR1 | sampleL2 | sampleR2 |
双通路压缩为adpcm数据为 4bytes block L head + 4bytes block R head + 4bytes raw L data + 4bytes raw R data…: adpcm双通路block head:
| byte 0 byte 1 | byte 2 | byte 3 | byte 4 byte 5 | byte 6 | byte 7 |
|---|---|---|---|---|---|
| sample0L | indexL | reservedL | sample0R | indexR | reservedR |
接着双通路raw压缩数据4byte L, 4byte R
| byte8 | byte9 | byte10 | byte11 | byte12 | byte13 | byte14 | byte15 | byte16 | byte17 | byte17 | … |
|---|---|---|---|---|---|---|---|---|---|---|---|
| data0L | data1L | data2L | data3L | data0R | data1R | data2R | data3R | data4L | data5L | data6L | … |
其中sample1编码后存data0低4位,sample2编码后存data0高四位...
需要特别留意双声道的处理和当数据不够1 block时的处理方式: 如果最后不够1block,多于1个,还按照1block进行编码,保存长度为1block。 如果最后只多余1个采样点,那就只保存blockheader,后面不用再保存了。 但在wav头告诉其实际采样点数,为将来解码还原相同的的采样点数。
四. 编解码代码实现
-
PC平台: https://github.com/ShowerXu/IMA-ADPCM 使用CodeBlocks打开编译
-
解码的单片机实现 在单片机中解码,最好是一个block的读取,所以在小内存中建议使用小的block,用flash换RAM占用。 下面是在stm32中的解码部分文件,供参考
这是我自己完成的基于PY32F003的内置Flash播放adpcm的例程,供参考。 pcmPlayer.zip